ペンシルパズルの「天体ショー」を整数計画問題として定式化してソルバーを使って解いてみた。
これは数理最適化 Advent Calendar 2020の19日目の記事です。
天体ショー
ペンシルパズルだとピクロスや数独が有名だけど、天体ショーもその一つ。
いろいろなペンシルパズルがあるけど、自分はこの天体ショーが大好き。
- 問題の図が星を散りばめたようになっていて、まさに「天体ショー」
- ルールが「点対称」を使ったものになっていて、「点対称」と「天体ショー」を掛けているのが素敵
- 解き終わったときにイラストが出てくるので、解く喜びが大きい
- 序盤はサクサクとテンポよく進み、中盤で考えどころがあって、大きなブロックを切り出せると興奮する
- 問題を作るのも比較的簡単(ドット絵を考えて、点対称な図形で区切っていけばいい)
そこで、天体ショーのソルバーを作ってみることを考えた。
人間が解くようにロジックを組んでいってもいいんだけど、整数計画問題として定式化さえできれば、汎用ソルバーで解くこともできる。
なので、今回は整数計画問題として定式化することを考えてみた。
ただ、検索してみると、すでに先人が。
鉛筆パズルの整数計画法による解法定式化集
(52番目に天体ショーがある)
なので、これを実装するだけかなと思ったんだけど、ちゃんと読んでみると問題があることが分かった。
連結制約
基本的な方針は、あるマスがある星に属するかどうかを0-1変数で表現する先人の方法でOK。
ただ、先人の定式化だと「ある星に属するマスがすべて連結している」という条件(以下、連結制約)をちゃんと表現できていないことに気がついた。
一応、「孤立したマスがない」「2マスだけが繋がったブロックがない」「L字型にだけ繋がったブロックがない」という条件は入っていて、これで大体OKだったらしい。
けど、次のような簡単な問題でも上記の制約だけではダメになる:
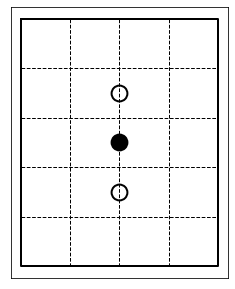
この問題の正しい答えは以下:

けど、先人の入れた制約だと、以下のような答えも正しいとなってしまう:
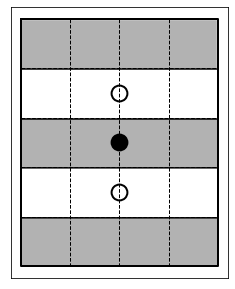
先人の制約はすべて守られているけど、明らかに上のブロックと下のブロックは真ん中のブロックと連結してないので、正しい答えになっていない。
じゃあ、どうすれば連結制約を正しく表現できるのか・・・?
これが想像以上に難しかった。
ああでもない、こうでもないと悩み続け、昨日やっと答えが分かった。
全域木
答えは「ブロックが全域木になっていることを表現する」というもの。
任意のブロックについて、マスを頂点、マスとマスの境界を辺と考えると、これはグラフになっていて、「ブロックが連結である」ことと「グラフに全域木が存在する」ことは同値になっている。
(※ここでは全域木の定義を「連結」で「閉路を持たない」グラフとする。単に「閉路を持たない」グラフは全域森)
そして、ブロックは星のあるマスから伸びていくと考えると、グラフに全域木が存在するなら、星のないマスはすべて、ただ1つの親を持つことになる。
(逆に、星のないマスがすべて、ただ1つの親を持つなら、グラフに全域木が存在する)
そこで、 として、マス
として、マス に対して、方向
に対して、方向 のマスが親かどうかを、変数
のマスが親かどうかを、変数 で表現することにする。
さらに、星のないマスに対して、星のあるマスまでのパスの長さを変数
で表現することにする。
さらに、星のないマスに対して、星のあるマスまでのパスの長さを変数 で表現することにする。
で表現することにする。
このとき、次の3つが制約として必要になる:
- 星のない任意のマスについて、親はただ1つ存在する

- 親のパスの長さは、子のパスの長さよりちょうど1小さい

(※  は十分に大きな正の整数で、子と親
は十分に大きな正の整数で、子と親 は隣り合っていて、
は隣り合っていて、 は適切な方向とする)
は適切な方向とする)
- 親は子と同じ星に属する

(※ 親は子に隣接していて、は適切な方向とし、変数 はマスが星
はマスが星 に属するかどうかを表すとする)
に属するかどうかを表すとする)
2つめの制約はちょっとテクニカルで、が親でないなら となるので実質意味のない制約になり、逆にが親なら
となるので実質意味のない制約になり、逆にが親なら なので子のパスの長さが親よりちょうど1大きいという制約になる。
なので子のパスの長さが親よりちょうど1大きいという制約になる。
また、最後の制約は、 (つまりがの親)かつ
(つまりがの親)かつ (つまりがに属する)のときに限り、左辺は1となって(それ以外は0以下)、そのときに限り
(つまりがに属する)のときに限り、左辺は1となって(それ以外は0以下)、そのときに限り (つまりもに属する)となる(それ以外は右辺は0でも1でもいい)ので、ちゃんと条件を表現できていることが分かると思う。
(つまりもに属する)となる(それ以外は右辺は0でも1でもいい)ので、ちゃんと条件を表現できていることが分かると思う。
(2020-12-26追記)
2.は元の制約だと閉路になる場合があったので、修正した。
PICOS
あとは他の制約なども数式で表現してソルバーに食わせればいいだけで、PythonからPICOS(+GLPK)を使って解いてみた。
ちなみに、PICOSはPuLPやOR-Toolsのようなライブラリなんだけど、類似したライブラリの中で一番Pythonっぽいコードが書けるので、自分は気に入ってる。
ソルバーもデフォルトでCVXOPTがついてきて、他にもGLPKやSCIP、あと持ってればCPLEXやGurobiも使える。
さらにはLPやMIPだけじゃなくてSOCPやSDPも解ける優れもの。
(知名度だけは低い・・・)
まず、問題はテキストで以下のように書くことにした:
-----------
| | |o|*|o|
--o--------
| | | * | |
---------o-
|o|*|o| | |
-----------
| * | |*| |
-----------
| |o| | |o|
-----------
oが白い星で、*が黒い星。
これを読み込んで情報を保持するために、MarkerクラスとProblemクラスを定義:
from enum import Enum
class Marker:
class Color(Enum):
WHITE = 0
BLACK = 1
def __init__(self, color, row, col):
self.color = color
self.row = row
self.col = col
class Problem:
@classmethod
def read_str(cls, contents):
lines = contents.splitlines()
row_size = len(lines) // 2
col_size = len(lines[0]) // 2
markers = []
for r_idx, line in enumerate(lines[1:-1]):
for c_idx, char in enumerate(line[1:-1]):
row = r_idx / 2
col = c_idx / 2
if char == 'o':
marker = Marker(Marker.Color.WHITE, row, col)
markers.append(marker)
elif char == '*':
marker = Marker(Marker.Color.BLACK, row, col)
markers.append(marker)
return cls(row_size, col_size, markers)
@classmethod
def read_file(cls, filepath):
with open(filepath) as f:
contents = f.read()
return cls.read_str(contents)
def __init__(self, row_size, col_size, markers):
self.row_size = row_size
self.col_size = col_size
self.markers = markers
そして、解く関数を以下のように定義:
※めっちゃ長い
import numpy as np
import math
import picos
directions = ['up', 'right', 'down', 'left']
def solve_by_picos(problem, solver='glpk'):
ip = picos.Problem()
ip.set_objective('find')
belong = {}
for row in range(problem.row_size):
for col in range(problem.col_size):
for i, marker in enumerate(problem.markers):
belong[row,col,marker] = picos.BinaryVariable(f'belong_{row}_{col}_{i}')
parent = {}
for row in range(problem.row_size):
for col in range(problem.col_size):
for direction in directions:
parent[row,col,direction] = picos.BinaryVariable(f'parent_{row}_{col}_{direction}')
for row in range(problem.row_size):
parent[row,0,'left'] = 0
parent[row,problem.col_size-1,'right'] = 0
for col in range(problem.col_size):
parent[0,col,'up'] = 0
parent[problem.row_size-1,col,'down'] = 0
distance = {}
for row in range(problem.row_size):
for col in range(problem.col_size):
distance[row,col] = picos.IntegerVariable(f'distance_{row}_{col}', lower=0)
for marker in problem.markers:
row_range = range(math.floor(marker.row), math.ceil(marker.row)+1)
col_range = range(math.floor(marker.col), math.ceil(marker.col)+1)
for row in row_range:
for col in col_range:
ip.add_constraint(belong[row,col,marker] == 1)
ip.add_constraint(distance[row,col] == 0)
for direction in directions:
parent[row,col,direction] = 0
for row in range(problem.row_size):
for col in range(problem.col_size):
belong_sum = sum(belong[row,col,marker] for marker in problem.markers)
ip.add_constraint(belong_sum == 1)
NOTE
for marker in problem.markers:
for row in range(problem.row_size):
opposite_row = int(2*marker.row - row)
for col in range(problem.col_size):
opposite_col = int(2*marker.col - col)
opposite_is_out = (
(opposite_row < 0) or (problem.row_size <= opposite_row)
or (opposite_col < 0) or (problem.col_size <= opposite_col)
)
if opposite_is_out:
ip.add_constraint(belong[row,col,marker] == 0)
else:
already_added = (
(opposite_row < row)
or ((opposite_row == row) and (opposite_col <= col))
)
if not already_added:
ip.add_constraint(belong[row,col,marker] == belong[opposite_row,opposite_col,marker])
for row in range(problem.row_size):
for col in range(problem.col_size):
parent_sum = sum(parent[row,col,direction] for direction in directions)
if type(parent_sum) != int:
ip.add_constraint(parent_sum == 1)
NOTE
M = problem.row_size * problem.col_size
for row in range(problem.row_size):
for col in range(problem.col_size):
for direction in directions:
if type(parent[row,col,direction]) != int:
if direction == 'up':
parent_row = row - 1
parent_col = col
elif direction == 'right':
parent_row = row
parent_col = col + 1
elif direction == 'down':
parent_row = row + 1
parent_col = col
else:
parent_row = row
parent_col = col - 1
dist_expr = distance[row,col] - distance[parent_row,parent_col] - 1
ip.add_constraint(dist_expr >= -M * (1-parent[row,col,direction]))
ip.add_constraint(dist_expr <= M * (1-parent[row,col,direction]))
NOTE
for row in range(problem.row_size):
for col in range(problem.col_size):
for direction in directions:
if type(parent[row,col,direction]) != int:
if direction == 'up':
parent_row = row - 1
parent_col = col
elif direction == 'right':
parent_row = row
parent_col = col + 1
elif direction == 'down':
parent_row = row + 1
parent_col = col
else:
parent_row = row
parent_col = col - 1
for marker in problem.markers:
ip.add_constraint(parent[row,col,direction] + belong[row,col,marker] - 1 <= belong[parent_row,parent_col,marker])
ip.solve(solver=solver)
answer = np.zeros((problem.row_size, problem.col_size), dtype=np.object)
for row in range(problem.row_size):
for col in range(problem.col_size):
for i, marker in enumerate(problem.markers):
if belong[row,col,marker].value == 1:
answer[row,col] = marker
break
return answer
詳細はコメントなどを読んでもらえれば・・・
これでちゃんと連結制約を守って問題を解くことができた。
最後に、自分でも天体ショーの問題を作ってみたので、貼り付けてみる:

鉛筆片手に解いてもらってもいいし、プログラムで解いてもいいので、楽しんでもらえればと思う。
上記のコードや、問題や解答をPNGで出力するコードは、以下のリポジトリを参照:
※上の問題の答えも入ってるので注意
数理最適化をテーマにした同人誌を書いてるので、よろしければこちらもどうぞ:
今日はここまで!

")




")







